Simulating and Loading Data
Damuta provides two classes for input data: DataSet and SignatureSet.
DataSet ensures that a counts dataframe and sample annotation can be easily aligned via matching on sample ids.
SignatureSet provides some simple methods for summarizing and understanding mutational signatures, as well for extracing damage and misrepair signatures from COSMIC-format signatures.
Simulating Data
We can simulate a dataset of mutation counts using the function sim_parametric. We will simulate 500 samples containing 10000 mutations each, with varying activities of 10 damage signatures, and 8 misrepair signatures.
[1]:
from damuta.sim import sim_parametric
counts, params = sim_parametric(S=500, N=10000, n_damage_sigs=10, n_misrepair_sigs=8, seed=1992)
counts.head()
WARNING (theano.tensor.blas): Using NumPy C-API based implementation for BLAS functions.
[1]:
| A[C>A]A | A[C>A]C | A[C>A]G | A[C>A]T | C[C>A]A | C[C>A]C | C[C>A]G | C[C>A]T | G[C>A]A | G[C>A]C | ... | C[T>G]G | C[T>G]T | G[T>G]A | G[T>G]C | G[T>G]G | G[T>G]T | T[T>G]A | T[T>G]C | T[T>G]G | T[T>G]T | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| simulated_sample_0 | 55 | 16 | 63 | 87 | 20 | 23 | 142 | 29 | 35 | 31 | ... | 157 | 162 | 42 | 66 | 59 | 95 | 49 | 29 | 76 | 50 |
| simulated_sample_1 | 122 | 92 | 133 | 135 | 73 | 43 | 116 | 19 | 17 | 22 | ... | 118 | 168 | 21 | 4 | 92 | 29 | 51 | 104 | 101 | 55 |
| simulated_sample_2 | 140 | 227 | 481 | 172 | 358 | 360 | 106 | 56 | 171 | 142 | ... | 24 | 23 | 23 | 13 | 53 | 55 | 57 | 10 | 43 | 4 |
| simulated_sample_3 | 19 | 18 | 38 | 56 | 9 | 190 | 31 | 35 | 75 | 29 | ... | 387 | 96 | 69 | 461 | 426 | 212 | 552 | 43 | 30 | 203 |
| simulated_sample_4 | 194 | 188 | 236 | 238 | 178 | 97 | 16 | 54 | 40 | 79 | ... | 18 | 95 | 15 | 8 | 34 | 7 | 22 | 134 | 80 | 63 |
5 rows × 96 columns
<Figure size 640x480 with 0 Axes>
Next, lets make use of DataSet to organize our data for us.
We will simulate some metadata annotate our 500 samples with. This is most applicable for pan-cancer data, and necessary when fitting Damuta’s HierarchicalTandemLda model, but the annotation slot of the DataSet is also useful for holding clinical metadata about each sample.
Note: Pan-cancer data is not required. All Damuta models can just as easily fit a dataset where all samples come from the same tissue type.
The DataSet class at minimum acts as a container for a pandas DataFrame of mutation type counts. The metadata annotation is also be a pandas DataFrame, in tidy format (ie. each row is a sample, each column is a feature). The DataFrame index of both the count data and annotation data is the sample id.
In this example, we simulated the counts dataframe, but in principle any trinucleotide count data that can be loaded with pd.read_csv can be used.
[ ]:
import numpy as np
import pandas as pd
import damuta as da
# pick from 3 tissues
tissues = np.array(["Breast-AdenoCA", "Kidney-RCC", "ColoRect-AdenoCA"])
# pick from primary or metastatic tumour
types = np.array(['primary', 'metastatic'])
# randomly assign tissue type to samples
annotation = pd.DataFrame.from_dict({"tissue_type": tissues[np.random.choice(3,500)],
"tumour_type": types[np.random.choice(2,500)]
})
annotation = annotation.set_index(counts.index)
annotation.head()
| tissue_type | tumour_type | |
|---|---|---|
| simulated_sample_0 | Breast-AdenoCA | primary |
| simulated_sample_1 | ColoRect-AdenoCA | metastatic |
| simulated_sample_2 | ColoRect-AdenoCA | metastatic |
| simulated_sample_3 | Breast-AdenoCA | primary |
| simulated_sample_4 | ColoRect-AdenoCA | metastatic |
Pair the counts and metadata with the DataSet class.
[3]:
simulated_data = da.DataSet(counts, annotation)
print(f"simulated_data contains {simulated_data.n_samples} samples")
print(simulated_data.ids[0:5])
simulated_data contains 500 samples
['simulated_sample_0', 'simulated_sample_1', 'simulated_sample_2', 'simulated_sample_3', 'simulated_sample_4']
Loading signature data
Lastly, let’s retrieve a set of mutational signatures from the COSMIC database.
[4]:
signatures = pd.read_csv("https://cancer.sanger.ac.uk/signatures/documents/452/COSMIC_v3.2_SBS_GRCh37.txt", sep='\t', index_col=0 , header=0)
COSMIC = da.SignatureSet(signatures.T)
print(f"COSMIC contains {COSMIC.n_sigs} signatures")
COSMIC contains 78 signatures
Every COSMIC mutational signature can be re-written as a product of a damage signautre and misrepair signature.
[5]:
from damuta.plotting import *
plot_damage_signatures(COSMIC.damage_signatures.loc[["SBS2", "SBS5", "SBS6"]])
plot_misrepair_signatures(COSMIC.misrepair_signatures.loc[["SBS2", "SBS5", "SBS6"]])
plot_cosmic_signatures(COSMIC.signatures.loc[["SBS2", "SBS5", "SBS6"]])
[5]:
<seaborn.axisgrid.FacetGrid at 0x2b4c3cf129a0>
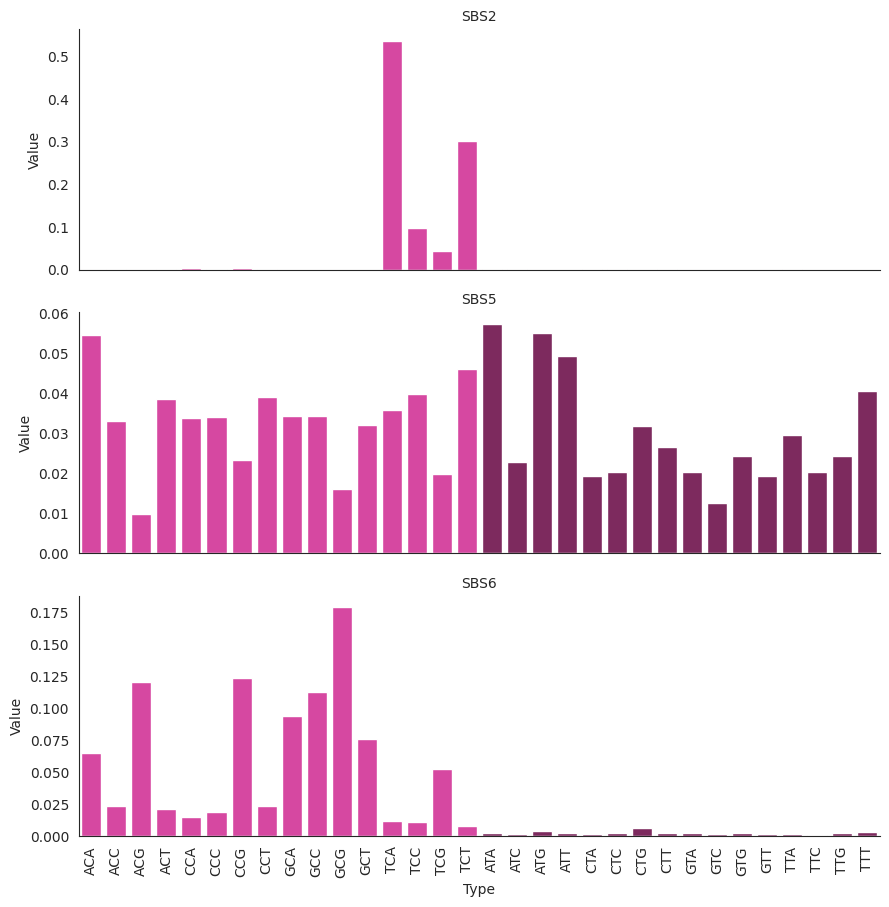
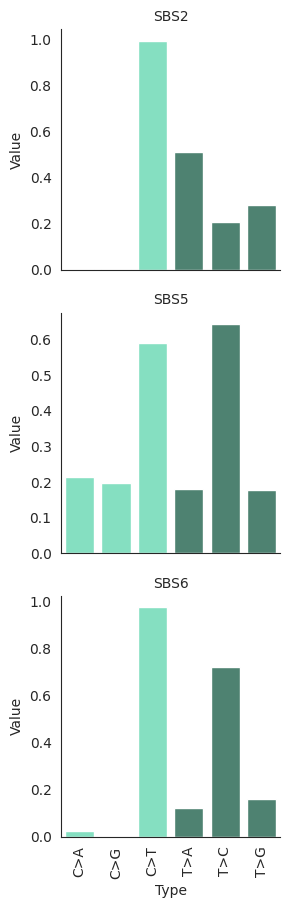
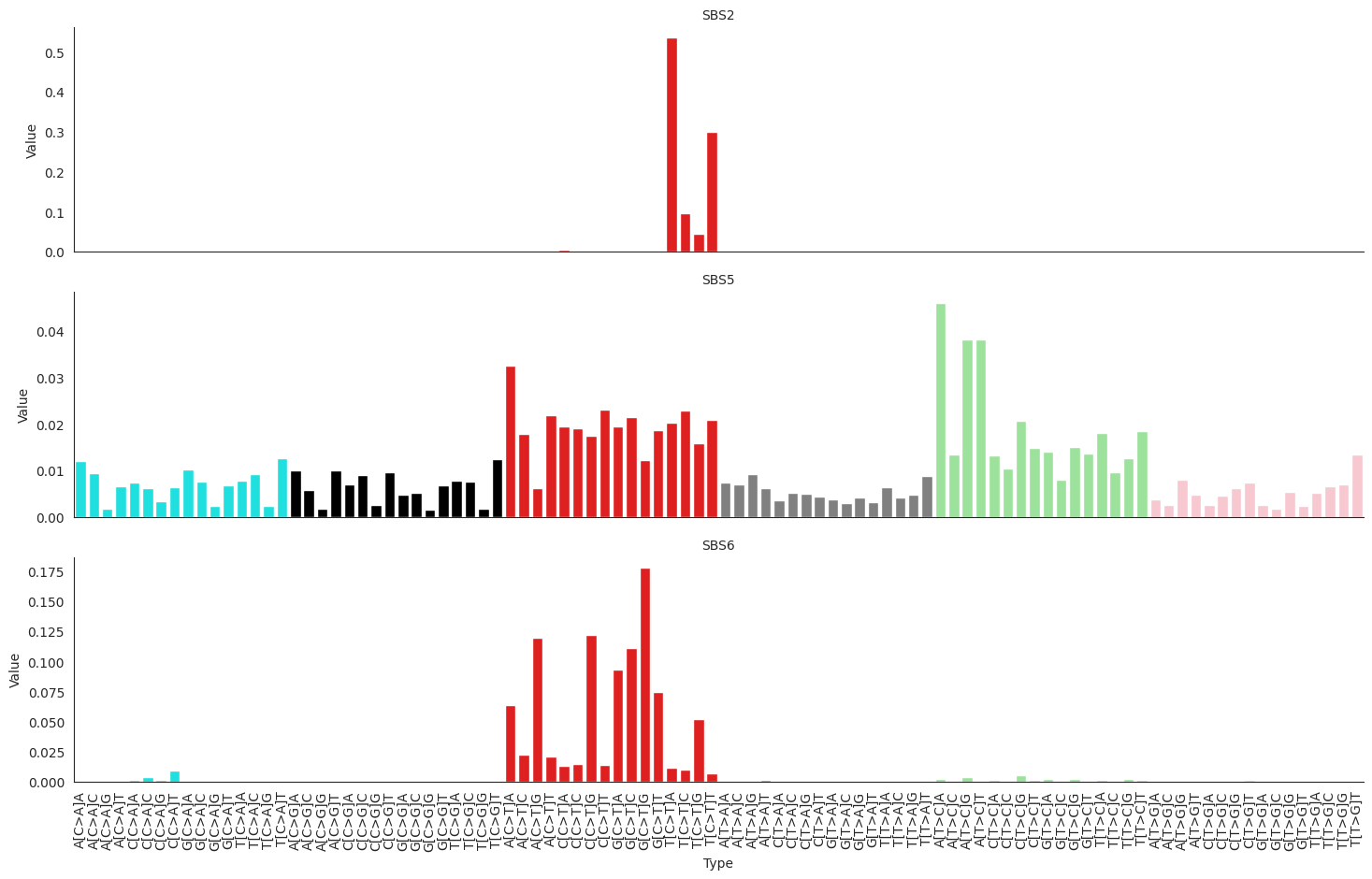
The COSMIC signautres are a high quality reference set, as can seen in their high degree of separation (low cosine similarity between different signatures). However there is higher similarity in the Damage and Misrepair aspects of this signature set.
[6]:
COSMIC.summarize_separation()
[6]:
| Mutational signature similarity | Damage signature similarity | Misrepair signature similarity | |
|---|---|---|---|
| count | 3003.000000 | 3003.000000 | 3003.000000 |
| mean | 0.188203 | 0.339645 | 0.684479 |
| std | 0.188601 | 0.240654 | 0.196205 |
| min | 0.000346 | 0.001997 | 0.194228 |
| 25% | 0.047759 | 0.137200 | 0.526309 |
| 50% | 0.118585 | 0.286935 | 0.703217 |
| 75% | 0.276046 | 0.518048 | 0.850554 |
| max | 0.979184 | 0.980951 | 0.999338 |
DAMUTA signatures
We can also initialize a signature set from just the damage and misrepair signature definitions.
[7]:
import os
os.chdir('/home/harrigan/damuta-package/docs/examples')
[8]:
DAMUTA = da.SignatureSet.from_damage_misrepair(
pd.read_csv('example_data/damage_signatures.csv', index_col=0),
pd.read_csv('example_data/misrepair_signatures.csv', index_col=0))
[9]:
plot_damage_signatures(DAMUTA.damage_signatures.loc[["D1", "D2", "D3"]])
plot_misrepair_signatures(DAMUTA.misrepair_signatures.loc[["M1", "M2", "M3"]])
[9]:
<seaborn.axisgrid.FacetGrid at 0x2b4c3e0e3a60>
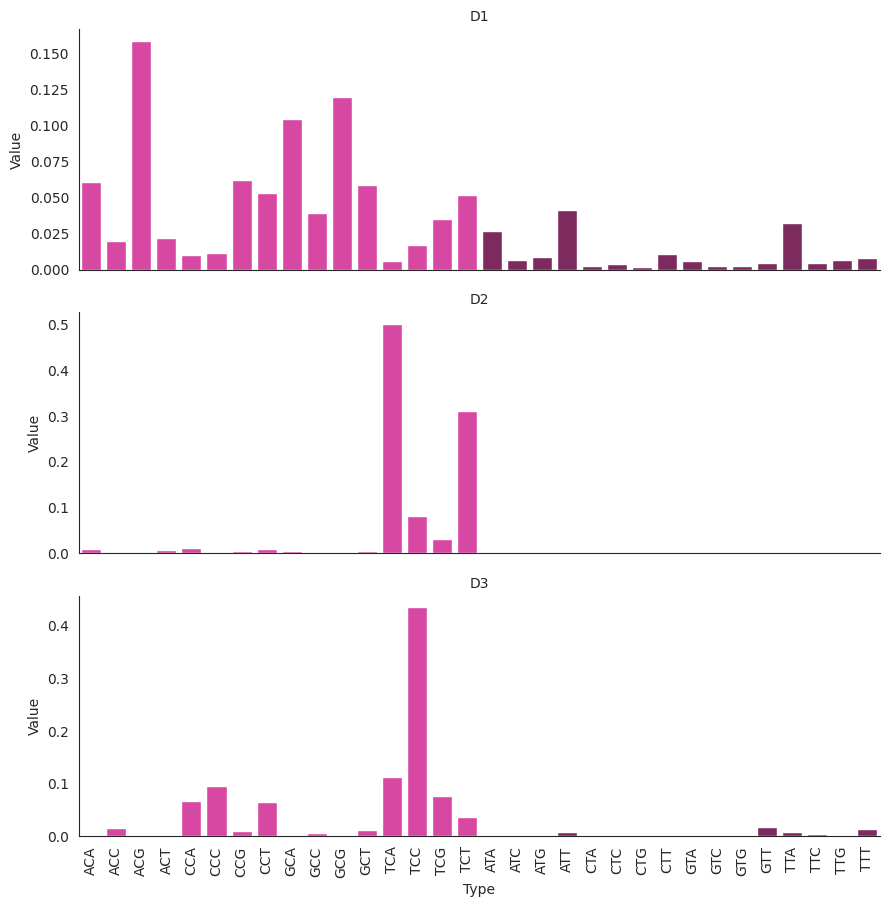
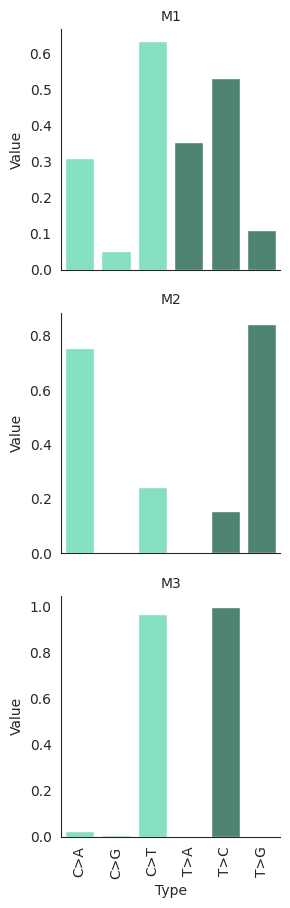
In this case, the signature set will also contain the outer product: all (unweighted) combinations of damage and misrepair signatures
[10]:
DAMUTA.signatures
[10]:
| A[C>A]A | A[C>A]C | A[C>A]G | A[C>A]T | C[C>A]A | C[C>A]C | C[C>A]G | C[C>A]T | G[C>A]A | G[C>A]C | ... | C[T>G]G | C[T>G]T | G[T>G]A | G[T>G]C | G[T>G]G | G[T>G]T | T[T>G]A | T[T>G]C | T[T>G]G | T[T>G]T | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| D1_M1 | 0.018900 | 0.006087 | 0.049454 | 0.006764 | 0.003098 | 0.003505 | 1.931383e-02 | 0.016475 | 0.032477 | 0.012318 | ... | 0.000178 | 0.001199 | 0.000683 | 0.000283 | 0.000313 | 0.000501 | 0.003581 | 0.000477 | 0.000749 | 0.000913 |
| D1_M2 | 0.045850 | 0.014768 | 0.119973 | 0.016409 | 0.007516 | 0.008502 | 4.685471e-02 | 0.039969 | 0.078787 | 0.029884 | ... | 0.001342 | 0.009065 | 0.005168 | 0.002140 | 0.002369 | 0.003789 | 0.027079 | 0.003609 | 0.005662 | 0.006902 |
| D1_M3 | 0.001538 | 0.000495 | 0.004024 | 0.000550 | 0.000252 | 0.000285 | 1.571713e-03 | 0.001341 | 0.002643 | 0.001002 | ... | 0.000005 | 0.000032 | 0.000018 | 0.000008 | 0.000008 | 0.000014 | 0.000097 | 0.000013 | 0.000020 | 0.000025 |
| D1_M4 | 0.001658 | 0.000534 | 0.004339 | 0.000593 | 0.000272 | 0.000308 | 1.694615e-03 | 0.001446 | 0.002850 | 0.001081 | ... | 0.000316 | 0.002132 | 0.001215 | 0.000503 | 0.000557 | 0.000891 | 0.006369 | 0.000849 | 0.001332 | 0.001623 |
| D1_M5 | 0.059906 | 0.019295 | 0.156753 | 0.021440 | 0.009820 | 0.011109 | 6.121874e-02 | 0.052222 | 0.102941 | 0.039046 | ... | 0.000079 | 0.000531 | 0.000303 | 0.000125 | 0.000139 | 0.000222 | 0.001585 | 0.000211 | 0.000331 | 0.000404 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| D18_M2 | 0.036187 | 0.088653 | 0.017828 | 0.138128 | 0.001980 | 0.006050 | 1.689988e-03 | 0.084667 | 0.033732 | 0.060501 | ... | 0.000455 | 0.001164 | 0.001911 | 0.002536 | 0.000773 | 0.001977 | 0.000882 | 0.001352 | 0.000847 | 0.000382 |
| D18_M3 | 0.001214 | 0.002974 | 0.000598 | 0.004633 | 0.000066 | 0.000203 | 5.668964e-05 | 0.002840 | 0.001132 | 0.002029 | ... | 0.000002 | 0.000004 | 0.000007 | 0.000009 | 0.000003 | 0.000007 | 0.000003 | 0.000005 | 0.000003 | 0.000001 |
| D18_M4 | 0.001309 | 0.003206 | 0.000645 | 0.004996 | 0.000072 | 0.000219 | 6.112254e-05 | 0.003062 | 0.001220 | 0.002188 | ... | 0.000107 | 0.000274 | 0.000449 | 0.000596 | 0.000182 | 0.000465 | 0.000207 | 0.000318 | 0.000199 | 0.000090 |
| D18_M5 | 0.047281 | 0.115832 | 0.023294 | 0.180473 | 0.002587 | 0.007904 | 2.208080e-03 | 0.110624 | 0.044073 | 0.079049 | ... | 0.000027 | 0.000068 | 0.000112 | 0.000148 | 0.000045 | 0.000116 | 0.000052 | 0.000079 | 0.000050 | 0.000022 |
| D18_M6 | 0.000021 | 0.000052 | 0.000010 | 0.000080 | 0.000001 | 0.000004 | 9.836452e-07 | 0.000049 | 0.000020 | 0.000035 | ... | 0.000117 | 0.000298 | 0.000489 | 0.000649 | 0.000198 | 0.000506 | 0.000226 | 0.000346 | 0.000217 | 0.000098 |
108 rows × 96 columns
[11]:
plot_cosmic_signatures(DAMUTA.signatures.loc[["D1_M1", "D7_M4", "D18_M6"]])
[11]:
<seaborn.axisgrid.FacetGrid at 0x2b4c3d53c9a0>
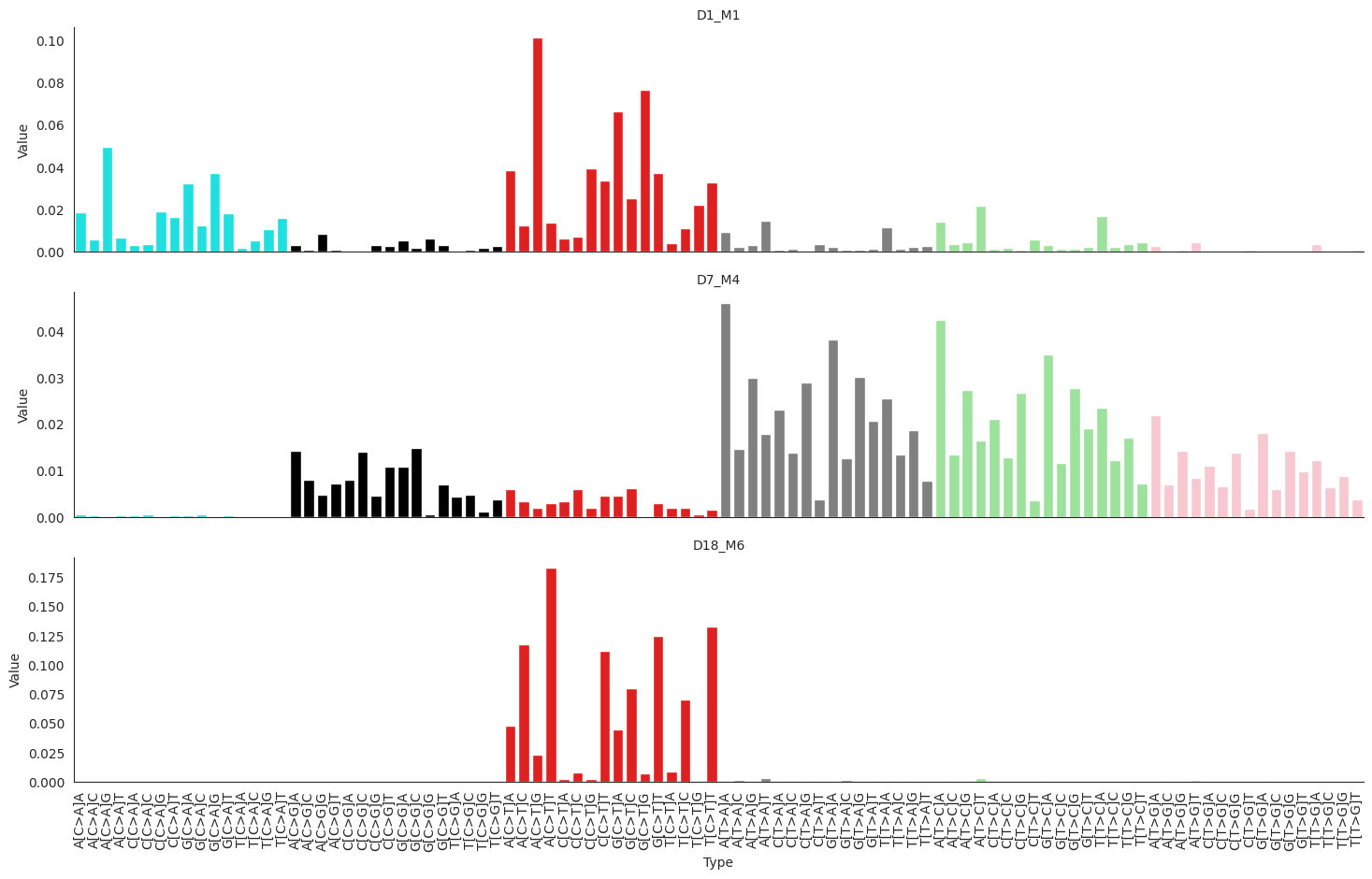
[12]:
DAMUTA.summarize_separation()
[12]:
| Mutational signature similarity | Damage signature similarity | Misrepair signature similarity | |
|---|---|---|---|
| count | 5778.000000 | 153.000000 | 15.000000 |
| mean | 0.176980 | 0.270253 | 0.524924 |
| std | 0.194173 | 0.209966 | 0.220816 |
| min | 0.000980 | 0.031818 | 0.254266 |
| 25% | 0.047516 | 0.120673 | 0.320952 |
| 50% | 0.109671 | 0.184103 | 0.504210 |
| 75% | 0.235473 | 0.367171 | 0.643424 |
| max | 0.999640 | 0.981909 | 0.893437 |